
Building a PHP CLI tool using DDD and Event Sourcing: the model
Last updated: 2023-08-21 :: Published: 2022-09-01 :: [ history ]You can also subscribe to the RSS or Atom feed, or follow me on Twitter.

The model is where the software meets the domain.
It is a technical expression of the domain that drives the development of the software but that is also understandable by the experts, who can validate it.
The goal of the model is to identify and express the use cases and constraints that will be built into the software, using schemas and diagrams. It is where we extract the essential concepts from the domain and where we consolidate the ubiquitous language.
In this series
- Why?
- The domain
- The model ⬅️ you are here
- Software design
- Setting up Laravel Zero
- Getting started with EventSauce
- Distribution
In this post
Modelling
There is no clear recipe to follow when it comes to modelling. Instead, there is a plethora of tools that we can leverage to express the model, some more or less suitable depending on the task at hand.
It's about finding the ones that will successfully inform the implementation of the software.
Transaction flowchart
I wasn't sure where to begin and looking online for answers was mostly adding to the confusion, everyone seemingly using a different approach.
To prevent inertia from settling in, I decided to have a go and to start with what was screaming at me the loudest – transaction processing.
I checked the domain article again and as I was going through the various rules and examples it contains, I realised that I was looking at a bunch of "if this then that" scenarios.
I picked up a marker and drew the following flowchart on a whiteboard:

How it started
While I couldn't fit in all the details, the diagram covered all the scenarios listed in the domain and connected them in a logical way, without obvious gaps.
I later made a digital version of it:

Transaction processing flowchart (made with Excalidraw – click here for a higher definition)
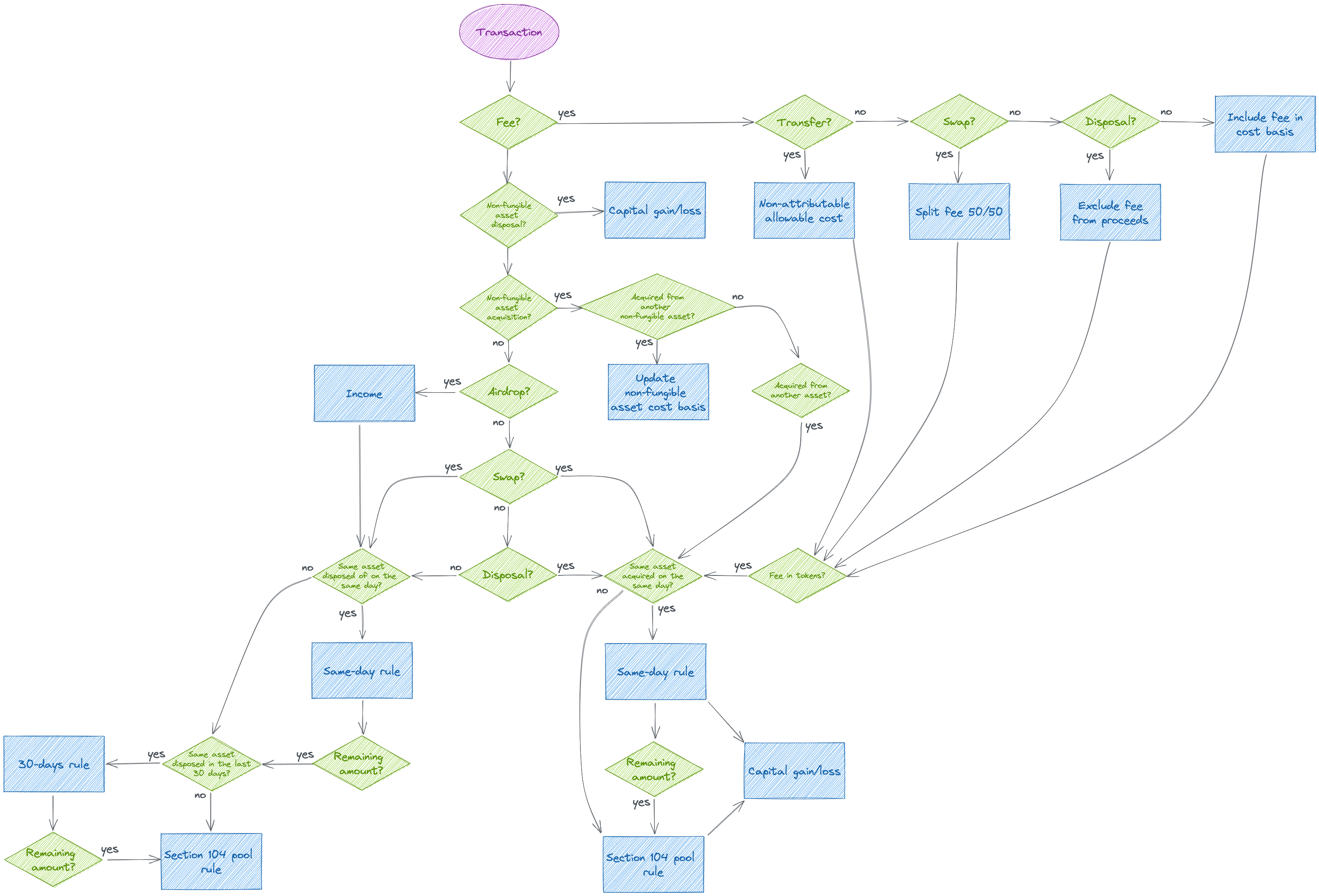{kind=link}
Wait. That is not the same diagram. That's because you are looking at an updated version of it, that I came up with later on, while working on the software's design. As I mentioned in the domain article, the different phases of DDD tend to feed into each other to get an increasingly clearer picture of what the software should be. The above diagram is the result of this process.
User stories
Looking at the flowchart, I realised I needed users to keep track of their transactions in a way that would satisfy the logic. So I started listing the reporting needs as user stories:
- As a user, I want my acquisitions to be processed as such, so I can get the correct figures
- As a user, I want my disposals to be processed as such, so I can get the correct figures
- As a user, I want my swaps to be processed as such, so I can get the correct figures
- As a user, I want my transfers to be processed as such, so I can get the correct figures
- As a user, I want fees to be identified in my transactions, so I can get the correct figures
- As a user, I want share-pooling assets to be identified in my transactions, so I can get the correct figures
- As a user, I want non-fungible assets to be identified in my transactions, so I can get the correct figures
- As a user, I want airdrops to be identified in my transactions, so I can get the correct figures
I went through the domain article again and added some implicit use cases not represented on the flowchart:
- As a user, I want my transactions to be processed in chronological order, so I can get the correct figures
- As a user, I want fiat amounts to be identified in my transactions, so I can get the correct figures
- As a user, I want cost bases to be identified in my transactions, so I can get the correct figures
- As a user, I want proceeds to be identified in my transactions, so I can get the correct figures
- As a user, I want the fees' market value to be identified in my transactions, so I can get the correct figures
- As a user, I want non-fungible assets swapped from other non-fungible assets to be identified in my transactions, so I can get the correct figures
- As a user, I want airdrops that should be counted as income to be identified in my transactions, so I can get the correct figures
- As a user, I want to report amounts in other currencies, so I don't need to convert them to British pounds myself
Note that I didn't mention hard forks nor gifts. The reason is that the former can be reported as regular acquisitions with a 0 cost basis, and the latter can also be reported as regular acquisitions, using the asset's market value at the time of the gift as the cost basis, or at the moment the asset was originally acquired by the gifter, if that person is the spouse of civil partner.
In both cases, a note can be added to the spreadsheet to mention that the acquisition came from a hard fork or a gift, but this is at the user's discretion, and not related to the software per se.
I then moved on to the submission process, for which I came up with the following stories:
- As a user, I want to submit my transactions as a CSV file, so I don't need to convert them to another format
- As a user, I want to submit my transactions as an Excel file, so I don't need to convert them to another format
- As a user, I want to submit a previously submitted file with new transactions, so I don't need to submit the new transactions only
- As a user, I want to select a specific tax year, so I don't get numbers for tax years I am not interested in
- As a user, I want to specify whether my activity is considered trading, so I can get the correct figures
That led me to the reviewing process, when the user goes through the data returned by the software:
- As a user, I want to see my capital gain, so I can complete my tax return
- As a user, I want to see my income, so I can complete my tax return
- As a user, I want to see my non-attributable allowable cost, so I can complete my tax return
- As a user, I want amounts to be expressed in British pounds, so I can complete my tax return
I thought of a couple more use cases for this one, extracted from the domain:
- As a user, I want to see my current balance in fiat terms, so I know whether I am in the black or in the green overall and by how much
- As a user, I want to know whether I am within the 30 days following the end of the tax year, so I am aware I should wait before completing my tax return
- As a user, I want to see my revenue beyond allowances, so I don't need to calculate this myself
Finally, there's a fourth category of stories that only came to me later, during the software design phase – exporting the results. Because while displaying the results in the terminal is nice, as a user I also want the possibility to save them to a file, for eventual access:
- As a user, I want to export my capital gain, income and non-attributable allowable cost to a CSV file, so I can complete my tax return
- As a user, I want to export my capital gain, income and non-attributable allowable cost to an Excel file, so I can complete my tax return
- As a user, I want to export my capital gain, income and non-attributable allowable cost to a PDF file, so I can complete my tax return
I ended up with a decent amount of user stories, but that wasn't the end of it. Not all stories bear the same weight and I now needed to classify them further to get a better sense of what would need to be built and when.
To that end, I resorted to a tool I had used before – a user story map.
User story map
User stories and user story mapping come from the Agile world and are not inherently DDD practices. But they provide valuable insights that we can use in a DDD context nonetheless.
To be honest I'm still not sure whether they are better suited for the model or the domain, but as they help both the experts (by listing user needs in a way they can understand) and the developers (by sketching the outlines of the software), the model seemed like a good fit.
A user story map is a visual representation of user stories. It's a way to logically group, sort and prioritise stories which also helps us identify the parts that we need to build together and separate them from the stories that can be dealt with later.
This is the user story map I came up with for the application. It's interactive, so you can have a look around and expand the various stories to see the detail:
Interactive user story map (made with Miro)
The blue rectangles at the top of each column are activities – higher-level groups of user stories. They match the four categories identified earlier – report, submit, review and export.
The yellow rectangles beneath them are steps – they represent sub-categories that put together form a complete activity.
Finally, the other rectangles are the details of each activity and step. They're essentially user stories, sorted by priority and broken down by iterations. Here, I've defined two iterations – the MVP and the backlog.
In other words, the application's MVP will be considered complete once all its user stories have been implemented. Other stories can then be picked up from the backlog to form a new iteration.
In short, the user story map provides both a roadmap for me to follow and a way to keep track of my progress. Moreover, it gives me an idea of the future bounded contexts and aggregates of the application, two key concepts of DDD.
I'll leave the aggregates aside for now as I consider them an implementation detail, but I'll cover bounded contexts in the next section, as these can inform the model.
Bounded contexts
I'm going to be honest here – I am unable to give you a precise definition for bounded contexts. Like most things DDD, everyone seems to have their own interpretation (here is one).
But the gist of it is to separate the various parts of an application and describe how they relate to each other. That latter part is usually done with a context map, which I drew below:

Context map (made with Excalidraw – click here for a higher definition)
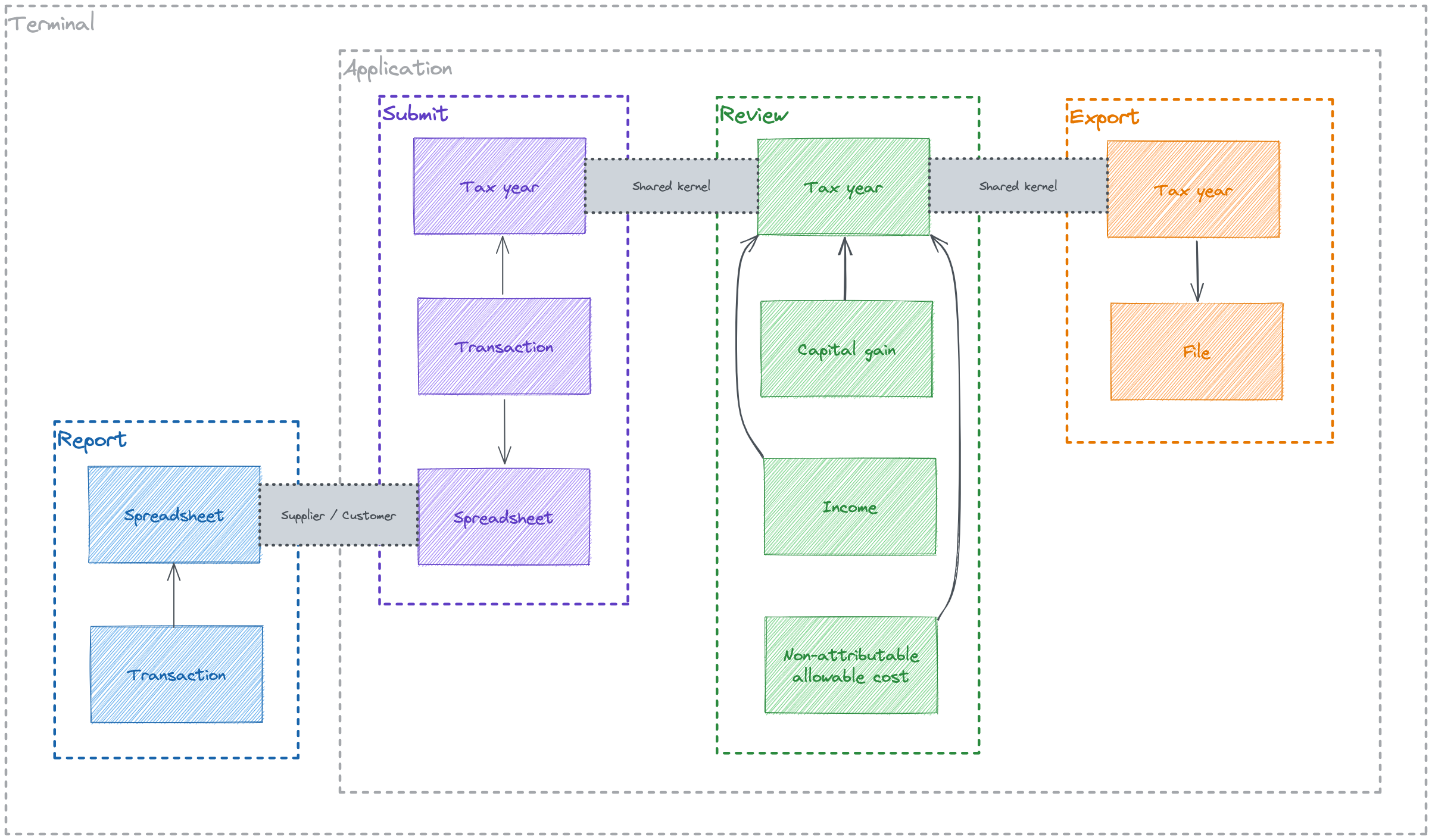{kind=link}
Note that the activities identified in the user story map have become bounded contexts.
Also note that the "Report" context is external to the application, as the transaction spreadsheet must be created and completed upstream. Its relationship with the application is one of customer-supplier – the provided file (supplier) must meet the expectations of the application (customer).
On the other hand, both the "Submit", "Review" and "Report" contexts are internal to the application, and the tax year object bridging them is likely to be the same for all. In other words, they have a shared kernel.
This is the extent to which I will cover bounded contexts. While they can be useful to model the domain, in this case I defined them for the sake of the exercise more than anything else.
Bounded contexts are often worked on by separate teams and considered to be distinct models with their own ubiquitous language. But this is a one-man show, and the size of the model doesn't warrant breaking it up anyway.
When it comes to this series, the context map is just an extra way to represent and think about the application.
Ubiquitous language
As the model is where experts and developers meet, it is also where they use a common language – the ubiquitous language.
We can go through the domain and analyse the diagrams and user stories to extract a glossary of key terms that will also be used within the software:
- 30-day period: The 30 days following the end of a tax year. Transactions occurring during that period may still count for the tax year that has just ended, because of the 30-days rule of pooling;
- 30-days rule: A share-pooling tax rule whereby assets acquired within 30 days of being disposed of must be matched with those disposals;
- Acquisition: An asset being acquired, in whichever way it may be;
- Airdrop: An asset being acquired in the context of a promotional operation;
- Allowable cost: A cost that can be deducted from other revenues, attributable to either an acquisition or a disposal;
- Allowance: An amount under which a tax regime doesn't apply;
- Application: The software processing the transaction spreadsheet and outputting results;
- Asset: A property whose acquisition or disposal is a taxable event;
- Capital gain: A profit realised when the proceeds of an asset disposal are greater than the cost basis of the acquisition, for assets falling under the Capital Gains Tax regime;
- Capital loss: A loss realised when the proceeds of an asset disposal are less than the cost basis of the acquisition, for assets falling under the Capital Gains Tax regime;
- Cost basis: The cost of acquisition of an asset, in fiat terms;
- Disposal: An asset being disposed of, in whichever way it may be;
- Disposal reversion: When an already processed disposal must be reverted due to a subsequent transaction falling under one of the share-pooling rules;
- Fee: An amount paid in exchange for a service;
- Fiat: A government-issued currency;
- Fiat balance: The total realised capital gain or loss, in fiat terms;
- Gift: An asset either received or given away for free;
- Hard fork: A protocol update leading to the split of a blockchain and the creation of a new asset;
- Income: An amount falling under the Income Tax regime;
- Market value: The value of an asset at a certain point in time, in fiat terms;
- Mint: The action of creating a non-fungible asset;
- NFT: A type of asset that isn't subject to share-pooling rules;
- Non-attributable allowable cost: A cost that can be deducted from other revenues, that can't be attributed either to an acquisition or a disposal;
- Non-Fungible Asset: A type of asset that isn't subject to share-pooling rules, like a NFT;
- Operation: Any operation involving an asset, as reported by the user;
- Proceeds: The amount obtained for an asset disposal, in fiat terms;
- Quantity: Any amount of an asset or fiat expressed as a number;
- Quantity allocation: Any quantity of a transaction that must be matched with another transaction's according to share-pooling rules;
- Remaining quantity: Any quantity left after one of the share-pooling rules has been applied;
- Report/Reporting: A user recording a set of transactions in a spreadsheet;
- Revenue: Generic term to design any type of income, be it dividends, capital gains, or anything else;
- Review/Reviewing: A user going through the application's output;
- Same-day rule: A share-pooling tax rule whereby assets acquired or disposed of on the same day must be matched with those acquisitions and disposals;
- Section 104 pool: An abstract container used as part of the share-pooling rules and in which the acquisitions of an asset are flowing to calculate the average cost basis;
- Section 104 pool rule: A share-pooling tax rule whereby the acquisitions of an asset are flowing into a pool to calculate the average cost basis;
- Share pooling: A set of tax rules applying to certain types of assets;
- Share-pooling asset: A type of asset that is subject to share-pooling rules;
- Software: The software processing the transaction spreadsheet and outputting results;
- Spouse or civil partner gift: An asset either received or given away for free, from or to a spouse or civil partner;
- Spreadsheet: A list of transactions as reported by the user;
- Submit/Submission: A user submitting a spreadsheet of transactions to the application;
- Swap: An asset being exchanged for another. Note that "swap" is preferred over "exchange" to avoid any confusion with the platforms where transactions are conducted;
- Symbol: An abbreviation representing an asset (e.g. BTC for Bitcoin);
- Taxable event: An operation which is subject to a tax regime;
- Tax return: The document tax payers have to submit to HMRC to declare their revenues;
- Tax year: The UK fiscal year, running from April 6 to April 5;
- Tax year summary: The report generated by the application for a specific tax year, featuring the capital gain, the income and the non-attributable allowable cost;
- Ticker: An abbreviation representing an asset (e.g. BTC for Bitcoin);
- Token: A property whose acquisition or disposal is a taxable event;
- Trading: Designates a user's crypto activity being considered a financial trade, thus falling under the Income Tax regime;
- Transaction: Any operation involving an asset, as reported by the user;
- Transfer: Moving an asset from one wallet to another, when both wallets belong to the user.
We came across most of these terms before, but by establishing a clear list like the above we crystallise them as words and expressions to use everywhere, including in the code.
Closing thoughts
I had the same difficulties approaching the model as I did the domain. Domain-Driven Design is very much an experience-driven discipline and starting out without proper guidance can be a bit overwhelming. It took me a while to identify the right tools to express the model in helpful ways, and I am still not sure how far I am supposed to go in doing so.
That being said, the next steps have already uncovered some gaps in the model and the domain, which I have updated accordingly. I trust I will keep getting a clearer picture over time.
The next instalment of this series will cover the application's software design, which flows directly from the model.
Subscribe to email alerts below so you don't miss it, or follow me on Twitter where I will share it as soon as it is available.
You can also subscribe to the RSS or Atom feed, or follow me on Twitter.